2021 Understanding Social Behavior in Dyadic and Small Group Interactions Challenge at ICCV
Challenge description
Overview
To advance and motivate the research on visual human behavior analysis in dyadic and small group interactions, this challenge will use a large-scale, multimodal and multiview (UDIVA) dataset recently collected by our group, which provides many related challenges. It will address two different problems, where context and both interlocutors’ information can be exploited due to the nature of our dataset.
The Tasks: The challenge will cover two different problems, divided into 2 tracks:
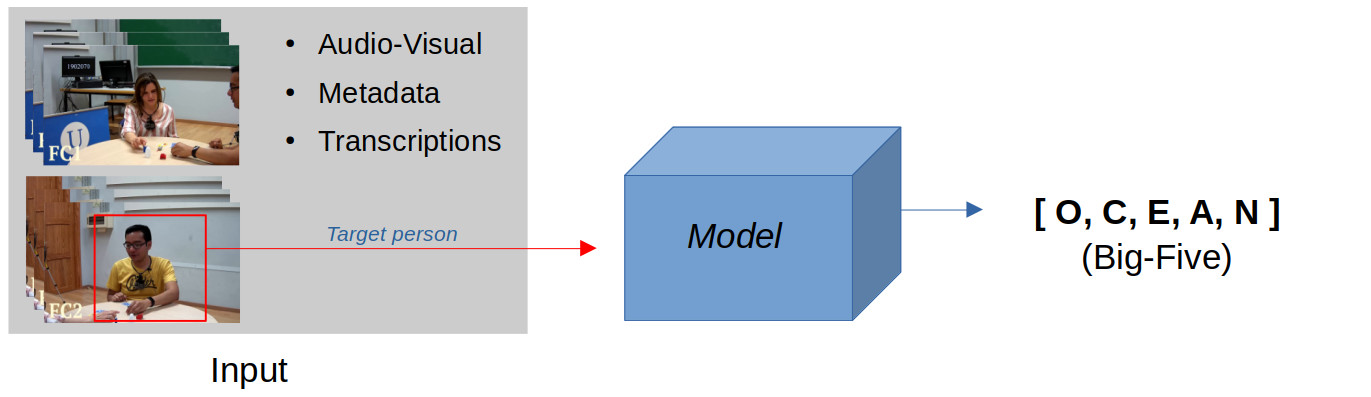
- Automatic self-reported personality recognition: this track will focus on automatic personality recognition of single individuals (i.e., a target person) during a dyadic interaction, from two individual views. Context information (e.g., information about the person they are interacting with, their relationship, the difficulty of the activity, etc.) is expected to be exploited to solve the problem. Audio-visual data associated with this track, as well as the self-reported Big-Five personality labels (and metadata information such as gender, type of interaction, if they know each other, and so on) are already available and ready to use. Utterance level transcriptions will be provided so that verbal communication can also be exploited.
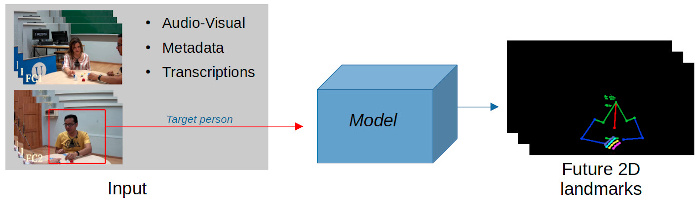
- Behavior forecasting: the focus of this track is to estimate future 2D facial landmarks, hand, and upper body pose of a target individual in a dyadic interaction for 2 seconds (50 frames), given an observed time window of at least 4 seconds of both interlocutors, from two individual views. Participants are expected to exploit context-aware information which may affect the way individuals behave. The labels used for this track will be automatically generated, i.e., they will be treated as soft labels, obtained using state-of-the-art methods for 3D facial landmarks, hand, and upper body pose estimation. We assume the training data may contain some noisy labels due to some small failures of the recognition methods. However, we will manually clean and fix wrong automatically obtained annotations in the validation and test sets in order to provide a fair evaluation. Challenge participants can also use context information and utterance-level transcriptions for this track.
Both tasks are multimodal, that is, audio-visual information and transcriptions will be given.
The Dataset: The UDIVA dataset aims to move beyond automatic individual behavior detection and focus on the development of automatic approaches to study and understand the mechanisms of influence, perception and adaptation to verbal and nonverbal social signals in dyadic interactions, taking into account individual and dyad characteristics as well as other contextual factors. To the best of our knowledge, there is no similar publicly available, non-acted face-to-face dyadic dataset in the research field in terms of number of views, participants, tasks, recorded sessions, and context labels. A preliminary version of the UDIVA dataset, UDIVA v0.5, will be used in both tracks of our ICCV 2021 Competition. Detailed information about the UDIVA v0.5 Dataset is given here.
The Phases: Each track will be composed of two phases:
- Development phase: public train data will be released and participants will need to submit their predictions with respect to a validation set;
- Test (final) phase: participants will need to submit their results with respect to the test data, which will be released just a few days before the end of the challenge.
Participants will be ranked, at the end of the challenge, using the test data. It is important to note that this competition involves the submission of results (and not code). Therefore, participants will be required to share their codes and trained models after the end of the challenge so that the organizers can reproduce the results submitted at the test phase, in a "code verification stage". At the end of the challenge, top-ranked methods that pass the code verification stage will be considered as valid submissions to be announced as top-winning solutions and to compete for any prize that may be offered.
Important Dates
A tentative schedule is already available here.
Dataset
Detailed information about the UDIVA v0.5 dataset is provided here.
Both competition tracks will use FC1 and FC2 views (highlighted in Figure 1 by a red rectangle). Challenge participants may use all the available data (videos, views and annotations) provided with the dataset for training; however, each track will use a particular set of videos and annotations for evaluation (validation and test), in particular:
- The automatic self-reported personality recognition track will be evaluated per subject, for which participants may use data from the 4 tasks (Talk, Lego, Animals and Ghost) highlighted by a green rectangle in Figure 2.
- The behavior forecasting track will be evaluated on specific 2-second segments of videos from the Talk task only, highlighted by a blue rectangle in Figure 2.
Segments used for behavior forecasting evaluation will be masked out on the original videos and transcripts. Since both tracks share the same data and data splits, these masked out videos/transcripts will be the ones to be used for the personality recognition track too.

How to get access to the UDIVA v0.5 Dataset?
-
First, you need to register on Codalab, and then in at least one of our ICCV'21 ChaLearn competition tracks (detailed next);
-
You will need to accept the Terms and Conditions;
-
Then, you will need to read thoroughly, fill in and duly sign the Dataset License, available on the "Participate" tab of the Codalab competition webpage, and return the signed license to us, following the instructions provided in the Dataset License. Please, note that:
-
There are 3 alternatives to sign and send us the license:
-
If you are based in the European Union, you can sign the license document with a digital certificate issued by a provider recognized by eIDAS, and send it to us via email to udiva@cvc.uab.cat.
-
For participants outside the European Union, you can use Docusign to sign the license. In that case, please send us an email to udiva@cvc.uab.cat with your team name and we will share the Docusign document with you.
-
For participants all over the world, you can also send us the original signed paper document by ordinary or certified mail to the address indicated in the License. In this case, we can only accept original signed paper documents, not scanned copies, nor documents with an embedded/copy-pasted signature from a picture. The signature must be handwritten.
-
-
The Dataset License must be signed by a researcher with a permanent/temporary position at a university or research institute, who will be considered to be the Licensee. Students are not allowed to sign the document nor be considered Licensees. Other researchers (subsidiaries and/or students) affiliated with the same institution may be named in the document as "additional researchers".
-
Students cannot be appointed as a contact point for data protection enquiries.
-
Teams only need one signed Dataset License even if they participate in both challenges.
-
Teams consisting of 2 or more university/research centers need to sign 1 dataset license per center.
-
Participants are welcome to send the filled document via email so that we can assess its validity prior to sending it via post.
-
-
After receiving the signed document and certifying its validity (as per the Dataset License clauses), we will send you the links to download the dataset and then the decryption keys to decompress the files by e-mail.
The deadline to request dataset access to participate in the challenge is July 31st, 2021.
How to enter the competition
![]()
The competition will be run on CodaLab platform. Click on the following links to access each of our ICCV'2021 Chalearn LAP Challenge tracks.
- Automatic self-reported personality recognition: Competition Track (link here).
- Behavior forecasting: Competition Track (link here).
The participants will need to register through the platform, where they will be able to access the data (after accepting the Terms and Conditions, fill in and sign the Dataset License following the provided instructions) and submit their predictions on the validation and test data (i.e., development and test phases) and to obtain real-time feedback on the leaderboard. The development and test phases will open/close automatically based on the defined schedule.
Baseline
Each track has an associated baseline, used for evaluation, briefly described below. Note that the organizer can submit new baseline results at any time, during the period of the challenge.
- Automatic self-reported personality recognition: for this track, we use a transformer-based method for self-reported personality inference in dyadic scenarios, which uses audiovisual data and different sources of context from both interlocutors to regress a target person’s personality traits. The method is detailed in the UDIVA paper.
- Behavior forecasting: for this track, we will use (1) the predicted joints from the last visible frame as a simpler baseline, and (2) a Seq2seq architecture for short-term face and body predictions with frozen hands as "baseline 2".
Starting kit
We provide a submission template for each track and phase (development and test), with evaluated samples and associated random predictions. Participants are required to make submissions using the defined templates, by only changing the random predictions by the ones obtained by their models. The evaluation script will verify the consistency of submitted files and may invalidate the submission in case of any inconsistency.
- Automatic self-reported personality recognition:
- Auxiliary code/instructions to perform the evaluation locally (e.g., using the train data) can be found in this repository.
- Behavior forecasting:
- Detailed instructions about the submission format can be found here.
- A ".csv" file with the start and end frames (both inclusive) of the segments to be predicted (per session) on the development phase can be found here, and the one used for the test phase can be found here. Note that the frame count on both ".json" and ".csv" files start from 0 (zero).
- In this repository you can find two demos: demo_evaluate.py which generates the baseline results (described in Baseline section) and evaluates them using the evaluation metric defined for this track. The plots are also stored. demo_visualize.py allows to generate a video with the annotations drawn.
Warning: the maximum number of submissions per participant (per track) at the test stage will be set to 3. Participants are not allowed to create multiple accounts to make additional submissions. The organizers may disqualify suspicious submissions that do not follow this rule.
Making a submission
To submit your predicted results on each track (and on each of the phases), you first have to compress your "predictions.csv" file (track 1) or "predictions.json" file (track 2) - please, keep the prediction filenames as they are - as "the_filename_you_want.zip". Then,
sign in on Codalab -> go to our challenge webpage on codalab (track 1 or track 2) -> go on the "Participate" tab -> "Submit / view results" -> "Submit" -> then select your "the_filename_you_want.zip" file and -> submit.
Warning: the last step ("submit") may take few seconds (just wait). If everything goes fine, you will see the obtained results on the leaderboard ("Results" tab). Note, Codalab will keep on the leaderboard the last valid submission. This helps participants to receive real-time feedback on the submitted files. Participants are responsible to upload the file they believe will rank them in a better position as a last and valid submission.
Evaluation Metric
The performances of the models on each track will be evaluated as follows.
- Automatic self-reported personality recognition: results will be evaluated with respect to the Average Mean Squared Error between the Big-Five personality trait prediction scores (p_i) and associated ground truth labels (g_i) for each individual (j) in the validation or test sets (given the N samples). As the same individual may appear in different sessions of the validation/test sets, individual IDs will be provided (detailed in Data Structure and Annotations) so that participants can "combine" the different results, given a target person, to generate a final prediction.
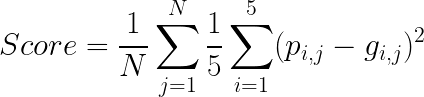
- Behavior forecasting: For each submission, three scores corresponding to face (F), body (B) and hands (H) predictions will be computed (detailed here). Participants will be ranked by the average rank position obtained on each of these three scores, as illustrated below.
![]()
Basic Rules
According to the Terms and Conditions of the challenge (available after you register on any of our Codalab Challenge Tracks, as detailed before) and the Dataset License document (found at the "Participate" tab of any of our Codalab Challenge Tracks),
- The UDIVA v0.5 Dataset will be used for the only purpose of participating in either of the two competition tracks. The licensor (Universitat de Barcelona) grants participants the right to use the Dataset, for its own internal and non-commercial use and for the purpose of scientific research only within the framework of the challenge.
- Participants having access to the UDIVA v0.5 Dataset agree not to redistribute the data in any form, and to delete the Dataset once the challenge has finished and all derived publications have been submitted, and in all cases no later than December 31st, 2021. Exceptions to this rule are described in the Dataset License.
- Participants may use any of the data modalities provided with the UDIVA v0.5 dataset to train their solutions, regardless of the competition track. Participants may also use additional third-party datasets to train their solutions, in addition to the provided training set.
- Track 2 (behavior forecasting): participants can use only information from previous frames to make a prediction for a given frame. Note that post-session fatigue and mood information is also considered future information, and therefore cannot be used. This behavior will be checked in the code verification stage and solutions which break this rule will be disqualified.
- The maximum number of submissions per participant (for each track) at the test stage will be set to 3. Participants are not allowed to create multiple accounts to make additional submissions. The organizers may disqualify suspicious submissions that do not follow this rule.
- At the end of the challenge, top-ranked methods that pass the code verification stage will be considered as valid submissions to be announced as top-winning solutions and to compete for any prize that may be offered. In addition to that, top-ranked participants’ score must improve the baseline performance provided by the challenge organizers.
- The organizers can submit (update) new results of the baseline method on each track and phase at any time.
- The performances on test data, for each track, will be verified after the end of the challenge during a code verification stage. Only submissions that pass the code verification will be considered to be in the final list of winning methods;
- To be part of the final ranking the participants will be asked to fill out a survey (fact sheet) where detailed and technical information about the developed approach is provided.
Sponsors
This event is sponsored by ChaLearn, 4Paradigm Inc., and Facebook Reality Labs. University of Barcelona, Computer Vision Center at Autonomous University of Barcelona, Human Pose Recovery and Behavior Analysis group, are the co-sponsors of the Challenge.
![]()

![]()
Prizes
Top winning solutions will be invited to give a talk to present their work at the associated ICCV 2021 ChaLearn workshop, and will have free ICCV registration covered by our sponsors. In addition to this, our sponsors are offering the following prizes:
Track 1: Top-1 solution: 1000$ / Top-2 solution: 500$ / Top-3 solution: 300$
Track 2: Top-1 solution: 1000$ / Top-2 solution: 500$ / Top-3 solution: 300$
Honorable mention: based on the significance of the result in a particular trait/s (track 1) or body part (track 2) and the level of novelty/originality of the solution, in addition to top-3 solutions, we may announce additional honorable mentions, which will also receive a winning certificate and a free ICCV registration.
Winning solutions (post-challenge)
Important dates regarding the code and fact sheets submission can be found here.
- Code verification: After the end of the test phase, participants are required to share with the organizers the source code used to generate the submitted results, with detailed and complete docker instructions or python virtual environment (and requirements) so that the results can be reproduced locally. Only solutions that pass the code verification stage are eligible to be announced as top-winning solutions and to compete for any prize that may be offered. For this, participants are required to:
- Share a docker image or a docker container on dockerhub with their codes and all required libraries installed, including links for download the pre-trained models and everything that should be needed to reproduce their results (e.g., hand-crafted features or additional train data), with step-by-step and detailed instructions to perform training AND testing. In the best scenario, the organizers should run no more than 3 commands or scripts to:
- Run the docker / install the python virtual env;
- Train the model;
- Make predictions (and generate the ouput file in the format of the challenge).
- Share a docker image or a docker container on dockerhub with their codes and all required libraries installed, including links for download the pre-trained models and everything that should be needed to reproduce their results (e.g., hand-crafted features or additional train data), with step-by-step and detailed instructions to perform training AND testing. In the best scenario, the organizers should run no more than 3 commands or scripts to:
- Fact sheets: In addition to the source code, participants are required to share with the organizers a detailed scientific and technical description of the proposed approach using the template of the fact sheets provided by the organizers. The Latex template of the fact sheets can be downloaded here below.
Instructions for both the code verification AND fact sheets should be provided as more detailed and complete as possible so that the organizers can easily reproduce the results.
How to share your code and fact sheets with the organizers? (new)
Participants are requested to share via email a link to a code repository with the required instructions, and the Fact Sheets using the provided template(s). Fact sheets must be shared as a compressed file (in .zip format), containing the generated PDF, .tex, .bib and any additional files required to generate the respective PDF. These information need to be sent to <juliojj@gmail.com> following the challenge schedule. In this case, put in the Subject of the E-mail "ICCV 2021 DYAD Challenge / Code and Fact Sheets"
** We encourage ALL participants to share their codes and fact sheets, independently of their rank positions. **
Challenge Results (test phase)
We are happy to announce the winning solution of track 1 and two Honorable mention award of the ICCV 2021 Understanding Social Behavior in Dyadic and Small Group Interactions Challenge.
They are:
- Automatic self-reported personality recognition:
- 1st place: hanansalam (SMART-SAIR team)
- Honorable mention award: f.pessanha (USTC-SLR team)
- Behavior forecasting:
- Honorable mention award: tuyennguyen (SAIR KCL team)
The final leaderboard (shown on Codalab), Codes and Fact Sheets shared by the participants can be found from the "Tracks" link in the menu of this website (upper left corner). Video presentations given by the authors of the above methods can be found here.
The organizers would like to thank all the participants for making this challenge a success.
Associated Workshop
Check our associated ICCV'2021 Understanding Social Behavior in Dyadic and Small Group Interactions Workshop.
News
DYAD@ICCV2021 Dataset access rules updated
It is now possible to request dataset access using a digital certificate! Please check the updated instructions here.
DYAD@ICCV2021 Validation set released
The masked-out validation set is available now for download.
DYAD@ICCV2021 Dataset access rules
The dataset access rules have been updated! Please check them out here.
ICCV 2021 Challenge
The ChaLearn Looking at People Understanding Social Behavior in Dyadic and Small Group Interactions Challenge webpage has been released.