2017 Looking at People CVPR/IJCNN Coopetition
Challenge description

ChaLearn Workshop on Explainable Computer Vision Multimedia and Job Candidate Screening Coopetition @CVPR17 and @IJCNN17
IJCNN - Anchorage, Alaska, May 2017
CVPR - Honolulu, Hawaii, July 2017
Aims and scope: Research progress in computer vision and pattern recognition has lead to a variety of modeling techniques with (almost) human-like performance in a variety of tasks. A clear example of this type of models are neural networks, whose deep variants dominate the arena of computer vision among other fields. Although this type of models have obtained astounding results in a variety of tasks they are limited in their explainability and interpretability. We are organizing a workshop and a competition on explainable computer vision systems. We aim to compile the latest efforts and research advances from the scientific community in enhancing traditional computer vision and pattern recognition algorithms with explainability capabilities at both the learning and decision stages.
Candidate screening coopetition:
This proposed challenge is part of a larger project on speed interviews. The overall goal of the project is help both recruiters and job candidates using automatic recommendations based on multi-media CVs. As a first step, we organized in 2016 two rounds of a challenge on detecting personality traits from short videos, for the ECCV 2016 conference (May 15, 2016 to July 1st 2016), see here and the ICPR 2016 conference (June 30 2016 to 16 August 2016), see here. This second round evaluated using the same data a coopetition setting (mixture of collaboration and competition) in which participants shared code. Both rounds revealed the feasibility of the task (AUC ~ 0.85) and the dominance of deep learning methods. These challenges have been very successful, attracting in total ~100 participants.
We propose for the competition programmes of IJCNN17 and CVPR 2017 a new edition of the challenge with the more ambitious goals to:
- Stage 1: Predict whether the candidates are promising enough that the recruiter wants to invite him/her to an interview (quantitative competition).
- Stage 2: Justify/explain with a TEXT DESCRIPTION the recommendation made such that a human can understand it (qualitative coopetition).
We will be using the same dataset, but with new annotations never used before about inviting the candidates for a job interview. For the quantitative task, the problem will be cast as a regression task (predict a continuous “invite-for-interview” score variable). For the qualitative task, a jury will decide whether the method developed proposes clear and useful explanations of recommendations.
In this new stage of the first impressions challenge, we are going several steps further:
- This will be the first time we will address the task of predicting “invite-for-interview”.
- We will also provide previous annotation data on personality traits (in training data only). This will encourage participants with work on algorithms in that benefit from learning both personality traits and hiring recommendations. In addition, predictions on personality traits could be also be exploited to explain decisions made.
- The competition will assess the explanatory capabilities of models, a topic that has not been previously considered in academic competitions. The topic of explainable computer vision and pattern recognition is very hot at the moment.
- We further explore the “coopetition” protocols (encouraging a mixture of collaboration and competition between the participants) using a new setting, for which we expect more participation.
Rules of the competition, including which data sets will be used
In the proposed competition, participants will develop solutions for predicting two types of variables (1) personality traits (context variables) and (2) whether a person should be invited to a job interview (decision variable), having as inputs short video sequences (see Figure 1). The variable of interest for the evaluation of the challenge will be “invite-for-interview”. In addition, participants will have to develop mechanisms that can explain the decision (recommendation) of the solution: i.e., to explain why (why not) would the developed solution rather invite a job candidate to an interview. The challenge is implemented as a collaborative competition, meaning that participants will have the opportunity to share part of their code and to receive points for this. The final evaluation of the challenge will consider: (1) performance for predicting the interview variable (quantitative evaluation, three winners); (2) performance of explanatory mechanisms using shared code from participants (qualitative coopetition evaluation, three winners).
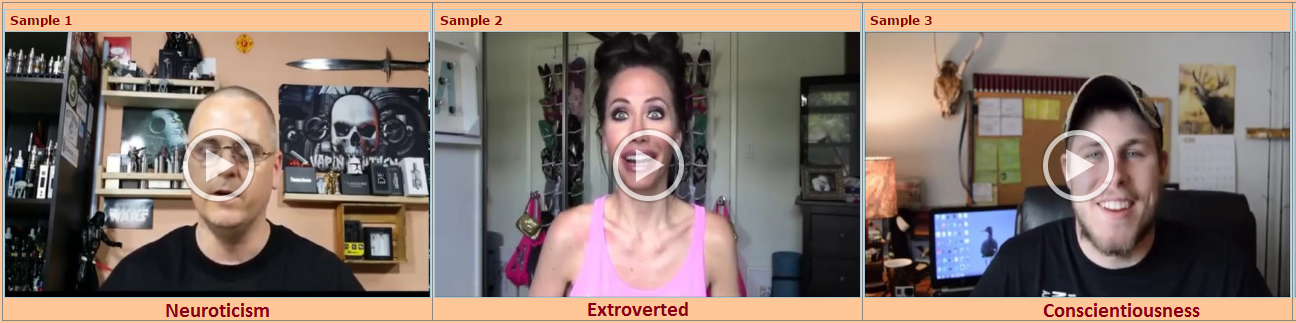
Figure 1: Snapshots of sample videos that will be used for the challenge.
For the competition we will use the first impressions dataset, a large newly collected benchmark with around 10,000 15-second videos collected from YouTube, and annotated by AMT workers. Each video was labeled with personality traits and the interview variable (a snapshot of the annotation tool is shown in Figure 2. The traits correspond to the “big five” personality traits used in psychology and well known of hiring managers using standardized personality profiling: Extraversion, Agreeableness, Conscientiousness, Neuroticism, and Openness to experience. In addition, annotators had to specify whether they think the person in the video should be invited to a job interview. The feasibility of the challenge annotations has already been successfully evaluated. Furthermore, the apparent trait annotations are highly predictive of invite-for-interview annotations with a significantly above-chance coefficient of determination of 0.91 (p≃0, permutation test). The data is further annotated to contain the transcriptions of the YouTube videos. Every 15 second YouTube video in the dataset is transcribed independently. The transcriptions are obtained using a professional human transcription service (www.rev.com) to ensure maximum quality of the ground truth annotations. This newly added data dimension will make it possible for competitors to use higher level, contextual information in their models.

Figure 2: Snapshot of the AMT labeling interface.
The proposed challenge is among the first efforts on benchmarking explainability of computer vision and pattern recognition methods, thus comprising a testbed for the development of explanatory mechanisms. Both the task proposed (job interviews) and the topic of explainability have important societal impact.
In the first two stages of our work using these data (predicting personality traits) deep learning methods have dominated. The task of predicting “invite-for-interview” is more difficult, so this will be a new challenge for computer vision researchers. Further, neural networks have been accused to be “black boxes”. Tackling the problem of explainability will have ramifications going far beyond addressing the tasks of the challenge.
How to enter the competitions and how to evaluate them
The competition will be run in the CodaLab platform (https://competitions.codalab.org), an open-source platform. The participants will register through the platform, where they will be able to access data, evaluation scripts, leaderboard in the validation data set (i.e., they can know their performance on validation data), etc. After registration in CodaLab, participants can access to the competition through here.
Evaluation
The challenge comprises three types of evaluations, each conveying its own assessment mechanism as follows:
- Quantitative evaluation (interview recommendation). The performance of solutions will be evaluated according to the performance of solutions when predicting the interview variable in the test data. However, the authors are expected to send predictions of personality traits and use them to improve their performance.
- Qualitative evaluation (explanatory mechanisms). Participants should provide a textual description that explains the decision made for "invite for an interview" in test data. Performance will be evaluated in terms of the creativity of participants and the explanatory effectiveness of the mechanisms-interface. For this evaluation we will invite a set of experts in the fields of psychological behaviour analysis, recruitment, machine learning and computer vision. Since the explainability component of the challenge requires qualitative evaluations and hence human effort, the scoring of participants will be made based on a small subset of the videos. Specifically, a small subset of videos from the validation data and a small subset of videos from the test data will be systematically selected to best represent the variability of the personality traits and invite-for-interview values in the entire dataset. The jury will only evaluate a single validation and a single test phase submission per participant. A separate jury member will serve as a tiebreaker.
- Coopetition evaluation (code sharing). Participants will be evaluated by the usefulness of their shared code in the collaborative competition scheme.
Both competition stages will be independently evaluated, and top 3 ranked participants at each stage will be awarded:
-1st stage of the competition (quantitative) will be evaluated in terms of regression error of the continuous "job interview recommendation" variable. Top 3 ranked participants will be awarded for this 1st quantitative stage.
-2nd stage of the competition: (qualitative coopetition). All participants that participate in this stage HAVE to provide their code from 1st stage. All participants in this stage can use any code from the rest of participants, fuse them, and provide the "explainable file of the recommendation" with the improved obtained results from this code sharing strategy. This second stage will be evaluated by the jury based on the following criteria. On a scale 0 to 5, 5 is best, evaluate the following:
-
Clarity: Is the text understandable / written in proper English?
-
Explainability: Does the text provide relevant explanations to the hiring decision made?
-
Soundness: Are the explanations rational and, in particular, do they seem scientific and/or related to behavioral cues commonly used in psychology.
-
Model interpretability: Are the explanation useful to understand the functioning of the predictive model?
-
Creativity: How original / creative are the explanations?
Results of the challenge will be presented at IJCNN17 and CVPR17. Winners of both competition stages will be invited to publish their work at CVPR 2017 associated workshop, to submit an extended version to the upcoming Springer series on Challenges in Machine Learning: Explainable models, and join a TPAMI paper with the organizers about the survey on the topic and competition. There will be travel grants (based on availability) for the winners.
News
January 10: CVPR 2017 competition started
Compatition on explainable impressions started and participants can enter the competiotion througth CodaLab here.