Large Scale Signer Independent Isolated SLR Dataset (CVPR'21)
Dataset description
Quick overview
AUTSL is a large-scale, multimode dataset that contains isolated Turkish sign videos. It contains 226 signs that are performed by 43 different signers. There are 36,302 video samples in total. It contains 20 different backgrounds with several challenges. We depict examples of different backgrounds from the dataset in the Figure below.

The dataset is recorded using Microsoft Kinect v2, hence it contains RGB and depth data modalities. We apply some clipping and resizing operations to RGB and depth data and provide them with the resolution of 512x512.
Data Split and Structure
The challenge dataset has been divided into three sub-datasets for user independent assessments of the models: train, validation, and test. We select 31 signers for training, 6 signers for validation, and the rest 6 signers for testing. Video names within each set are as the following:
- signerX_sampleY_color.mp4: Video with the RGB data.
- signerX_sampleY_depth.mp4: Video with the Depth data.
The ground truth of the train data contain the following information:
- Each row format: signerX_sampleY, label
The validation and test sets are only provided the samples, no labels (however, validation labels will be released for the final phase).
Please note that signer ids range goes from 0 to 42, sample ids range goes from 0 to 225.
Basic Statistics
AUTSL has 2 test sets: balanced and imbalanced. Balanced test set is a subset of the imbalanced test set. In this challenge, we release only the balanced test set. Therefore, the total sample number is 36,302. In the associated publication, the validation split was not designed as a user independent set; it was generated using a random split, i.e. 15% of the train data. For this challenge, we split the training set as non-overlapping training and validation splits, to create a validation set similar to the test set for the challenge evaluations. Then, we trained the same model using the same procedures as described in the paper, using the user independent training set in order to provide baseline results. In the Table below, we show some basic information about the dataset used in the challenge.
| Train | Valid | Test | Total | |
| Num of samples | 28,142 | 4,418 | 3,742 | 36,302 |
In the following figure, we provide the distribution of the samples over signs and signers. As shown in the figure, we have a balanced dataset according to the sign distribution. On the other hand, the total number of samples for some signers is higher than that of others (b). This is because they are recorded multiple times with different clothes or in different background settings.
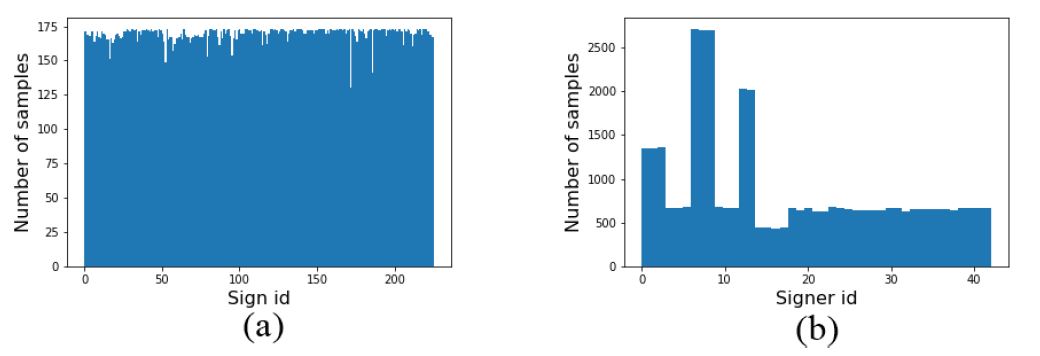
Out of 43 different signers; 6 of them are TSL instructors, 3 are TSL translators, 1 is deaf, 1 is coda (Children of Deaf Adults), 25 are TSL course students and 7 are trained signers who learned the signs in our dataset. 10 of these signers are men and 33 are women; and also, 2 of our signers are left-handed. The ages of our signers range from 19 to 50, and the average age of all signers is 31.
Links for Download
You can download the dataset used in the challenge from the following links. By downloading the data, you agree with the Terms and Conditions of the Challenge. All files are encrypted! To discompress the data, use the associated keys. Note, decryption keys are provided on Codalab after registration, based on the schedule of the challenge.
News
There are no news registered in Large Scale Signer Independent Isolated SLR Dataset (CVPR'21)